When managing big software projects, it is important to configure code rules for loads of scenarios. Usually, you start with basics, like prohibiting unused variables, requiring super() calls in subclass constructors, or catching duplicate conditions in if-else blocks.
In JavaScript / TypeScript projects that is handled by standard ESLint plugins: @eslint/js, typescript-eslint, eslint-plugin-react, etc. They are more or less easy to configure (ignoring the new flat config which adds the fun of guessing which plugins support it and which don’t yet), and this is where most tech leads stop.
However, the bigger the project, the more dependencies and opinionated patterns of doing something it accumulates. Large packages may have separate ESLint plugins maintained by independent contributors, but sometimes you’ll want to enforce a rule that doesn’t exist in any plugin. This becomes very important when you expect many people to work on the project, or if you want to use AI agents to write acceptable production code without thorough manual review.
The good news: ESLint lets you create almost any rule you can imagine! You don’t need to know specifics of ESLint scripting, since ChatGPT successfully manages to write 95% of the logic, and the remaining 5% would be easy finish when you see selector structure and regex patterns.
Here, I want to share a specific example. On my current frontend project we use Typescript, React, and Next.js with zustand for client-side state storage. To persist state after a page reload, I added the persist plugin that writes and reads data from browser’s localStorage. The problem is, Next.js renders client-side components twice: first time on server, then in browser, and both renders must match. However, the server doesn’t have access to client data, and the store state differs between environments, unless it was not used before.
The fix is to run rendering with an empty store, and then reading the state specifically on client side. In this case, both server and browser use the same empty state during the first render. This is achieved by using a custom hook, useStore, which returns an empty initial state and loads the actual state on client inside a useEffect:
export function useStore<T, F>(
store: (callback: (state: T) => unknown) => unknown,
callback: (state: T) => F,
) {
const result = store(callback) as F;
const [data, setData] = useState<F | undefined>(undefined);
useEffect(() => {
setData(result);
}, [result]);
return data;
}
Now state can be retrieved like this:
import {uiStore} from '@/store/ui';
import {useStore} from '@/hooks/useStore';
const visiblePanels = useStore(uiStore, (state) => state.dashboard.visiblePanels); ✅ correct
const visiblePanels = uiStore((state) => state.dashboard.visiblePanels); // ❌ wrong!
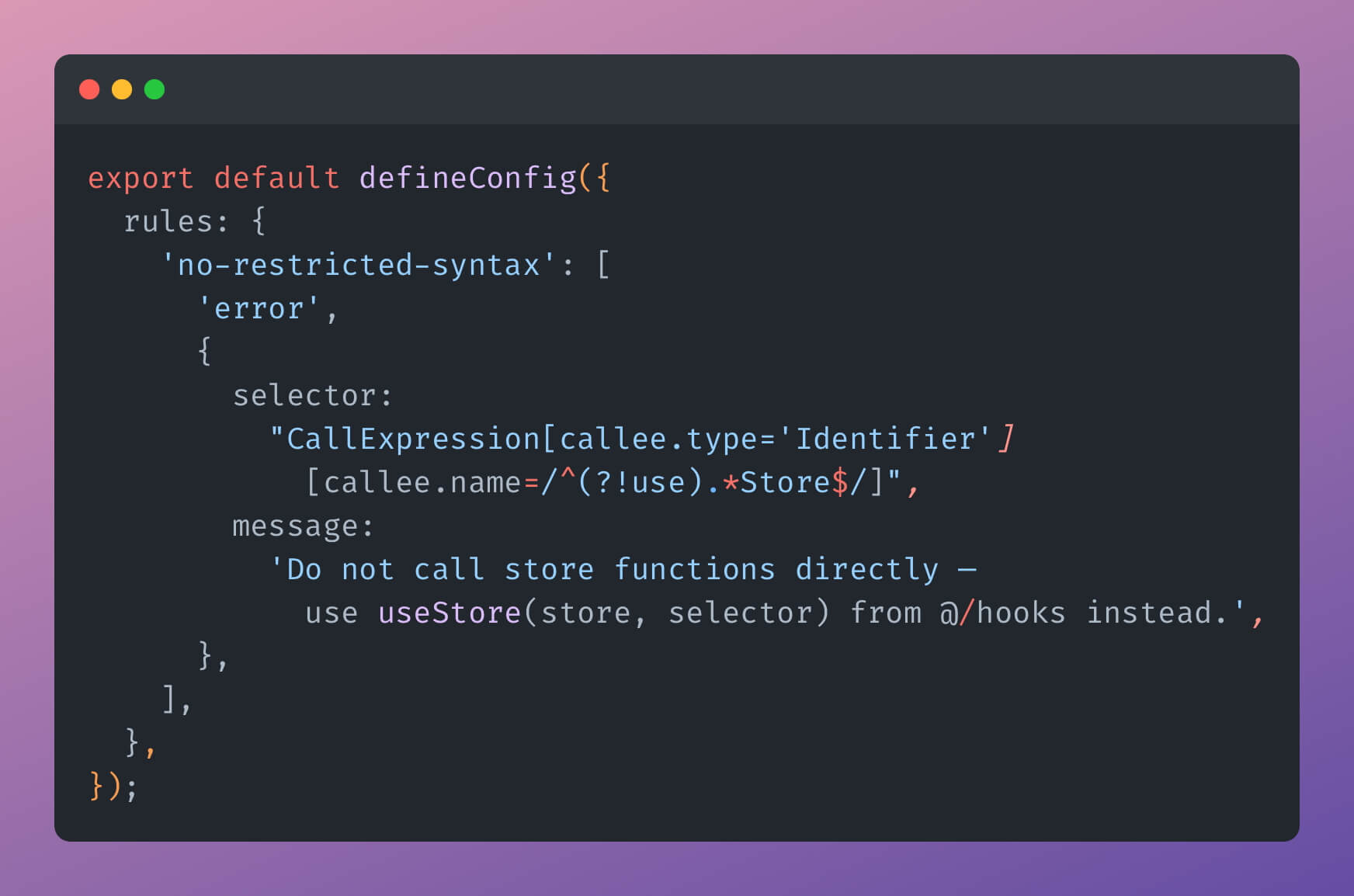
A problem is, nothing in this setup stops someone from using the wrong pattern. Moreover, the wrong way is the default in normal conditions, so any new developer or AI model are likely to use it. Here is where ESLint magic comes useful:
// eslint.config.mjs
export default defineConfig([
// ...necessary plugins here...
{
rules: {
'no-restricted-syntax': [
'error',
{
selector: "CallExpression[callee.type='Identifier'][callee.name=/^(?!use).*Store$/]",
message: 'Do not call store functions directly — use useStore(store, selector) from @/hooks instead.',
},
],
},
},
]);
This way we tell ESLint to watch for any invocation of functions whose name ends with a Store, except for useStore — our custom hook. Direct usage will be flagged, so the new devs or models will be able to correct themselves. Surely, someone could write a store with a name different from useSomethingStore, but this naming format is common and default by docs, so we stay on a safe ground here.
With this approach, you can enforce any code style, variable usage rule, import restriction, or architectural constraint. Add them, use them, and may your code be impossible to write in a wrong way.